
Introduction to Kubernetes Custom Resources
Reading Time: 7 minutesKubernetes is one of the most impactful open-source software in the last 10 years. Among others, it brings the myth(?) dreamed of auto-scalability. Apart from that, a Kubernetes environment is capable to take care of the applications we deploy within it, ensuring the desired state, and trying to keep the zero-downtime status. What about the Kubernetes Custom Resources?

In this article, we will focus on a very powerful feature that Kubernetes provides to its customer, which is the Kubernetes Custom Resources, describing what it is, how to create and manage them, and some use cases. Engage!
A short and fast introduction to Kubernetes
Kubernetes, also known as K8s, is an open-source system for automating deployment, scaling, and management of containerized applications.
kubernetes.io

Basically, it’s a software that keeps your applications, deployed as Containers, running in an environment that allows you, as operator/SRE/Developer/etc, to scale such deployments in a very flexible manner.
There are many companies that offer today a Kubernetes Managed Service, like AWS with its Elastic Kubernetes Service, or Google with its Google Kubernetes Engine (GKE). Also, there are some solutions to run Kubernetes on your local machine, like Minikube or KIND (love this one).
Another beauty of Kubernetes is that it offers a REST API that can be used by other applications to manage the objects (Pods, Deployments, ConfigMaps, Services, etc) within an environment. One of the endpoints of that REST API is meant to manage the Custom Resources, which is the kind of object we will focus on this article.
Introducing the Custom Resources and Custom Resource Definition
A custom resource is an extension of the Kubernetes API that is not necessarily available in a default Kubernetes installation. It represents a customization of a particular Kubernetes installation. However, many core Kubernetes functions are now built using custom resources, making Kubernetes more modular..
kubernetes.io
In other words. In the same way that Kubernetes comes with a builtin set of endpoints to manage objects like Pods, Deployments, or ConfigMaps (among others), Kubernetes offers a way for us, as users, to define custom objects (Custom Resource) to manage them via a custom endpoint.
There are 2 ways to create custom resources but, in this article, we will focus on the one I think it’s more common: Via Custom Resource Definition (CRD). Also, as with any object in Kubernetes, we can create CRDs via a YAML file or the REST API and, in this article, we will illustrate it via a YAML file.
Please note that this is a medium/advanced topic. In case you feel lost, I would encourage you to read the official documentation about Custom Resources before continuing.
Hello World Kubernetes Custom Resource
Let’s assume you already have in place a Kubernetes cluster to play with and use it for this Hello World. In case you don’t, I encourage you to invest a couple of minutes to set up one via KIND tool.
What are we gonna do in this chapter? We will create a Custom Resource Definition (CRD) and a Custom Resource (CR) based on the previous definition. Then, we will deploy both in a Kubernetes cluster and browse them. At the end of this section, you should have a better understanding about how Custom Resources work and how to create your own.
To drive this chapter, we will follow an example that defines a configuration for a Kafka topic. This definition will have
- The name of the Kafka topic
- The list of servers for the Kafka topic on which the Kafka topic is present
The Custom Resource Definition
First, we have to create the definition for our custom resource, so the Kubernetes cluster will identify correctly the future Custom Resources for our Kind. So, let’s see the code and later a brief explanation about how it works.
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: kafkatopics.marcosflobo.com
spec:
group: marcosflobo.com
scope: Namespaced
names:
plural: kafkatopics
singular: kafkatopic
shortNames:
- mykfkt
kind: KafkaTopic
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
metadata:
type: object
properties:
name:
type: string
spec:
type: object
properties:
kafka:
type: object
properties:
topic:
type: string
servers:
type: array
items:
type: object
properties:
dns:
type: string
required: ["dns"]
required: ["topic"]First important attribute, the metadata.name. This will be the name of the CRD.
Then, within the spec block, you can see plural, singular and shortNames, which are kind of intuitive.
The Kind attribute is important as well because is the name of the object within Kubernetes (please note that it’s different from metadata.name), like the builtin existing Pod, Deployment, etc.
Now, I’ll jump directly into the spec.versions.schema.openAPIV3Schema.properties.spec since it’s the block on which we can define the allowed attributes that can (will) be included in the future Custom Resources from the Kind KafkaTopic.
On this block, we are defining a new block named kafka. Within it, we define 2 sub-blocks
topic, which is directly a String type, and is meant to hold the name of the topicservers, which is a list (array) ofdnsnames (type String) for each URL of the Kafka cluster (a Kafka cluster may have several DNSs)
Last, but not least, you can find at the end of each defined block, the “required” properties.
In the incoming chapters, you will find an example of a Custom Resource for this CRD that we just defined, and the commands to deploy both CRD and CR in a Kubernetes cluster.
The Custom Resource
Good!. Now that we have the CRD defined, we can write down a Custom Resource based on such definition.
In this case, we are writing a CR named mykafkatopic that will hold the topic name and a list of 3 DNS that points to the Kafka cluster.
apiVersion: marcosflobo.com/v1
kind: KafkaTopic
metadata:
name: mykafkatopic # The name of the custom resource.
spec:
kafka:
topic: "marcosflobo_example_messages"
servers:
- dns: kafka1.marcosflobo.com
- dns: kafka2.marcosflobo.com
- dns: kafka3.marcosflobo.comDeployment
Brilliant! (as someone said). So far, we have written the Custom Resource Definition and a Custom Resource for it. Now, it’s time to deploy this and see how it works!
First, we have to deploy the CRD, the definition, otherwise, the Kubernetes cluster will not be able to recognize the Custom Resource for our Kafka configuration.
$ kubectl apply -f crd.yamlAnd, now, you can see (via K9S for example) that our beautiful Custom Resource Definition is there, in the K8S cluster, indicating the version/s available, and its age.
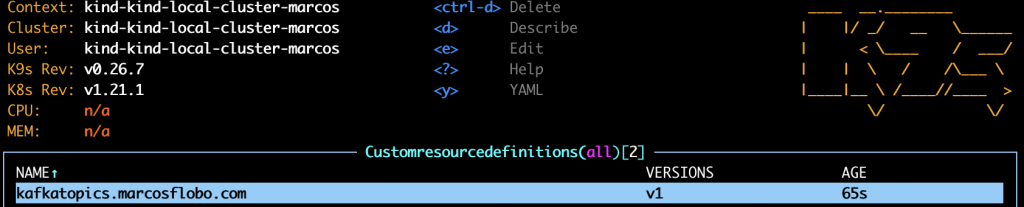
Now, we are in a position to deploy our first Kafka configuration as a Custom Resource. Let’s go for it.
$ kubectl apply -f example.yamlAnd there it is. If we enter in the kafkatopics.marcosflobo.com CRD, we can see the list of Custom Resources deployed for such definition. And our first one is named, in a burst of imagination, “mykafkatopic”
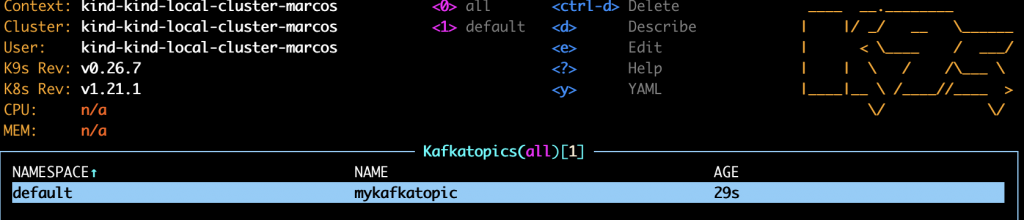
Recap of the Hello World
Ok, a couple of YAML files and a set of bash commands but… what do we have at this point?.
At this point, we have, in a Kubernetes cluster, the configuration to access a Kafka topic that exists in a Kafka server. With this information, any microservice running on the K8S cluster would be able to access this information, in a generic way, so then such applications could connect to the topic and produce/consume messages.
You can find the source code at https://github.com/marcosflobo/k8s-crd-example
Use cases
All the use cases on which I personally see Kubernetes Custom Resources very useful are about decoupling microservices within a Kubernetes cluster.
Distribution of configuration. Using a CRD, and the resultant CRs, you could deploy configurations that other microservices could use during their life cycle. We saw this use case in our Hello World example. It could be expected that microservices deployed in a Kubernetes cluster could use the Kubernetes API to get access to its context. By doing this, you are using the Kubernetes API (extended version) as a standard way to access the configuration that your microservices use/require.
Abstraction for automations. The Custom Resources can be used as a mechanism to trigger actions within a platform. Thanks to the WATCH API, special applications (Kubernetes Controllers) can detect when a Custom Resource for a certain Kind is deployed/modified/deleted, and act based on such action. For example, reading a CR to create/delete Kafka topics in a Kafka cluster.
Single responsability. Should my microservice know how a special type of record is inserted in the Dynamo DB used by a central microservice of my platform? Most likely, no. However, my microservice still needs that special type of record inserted into the database. How could I do that without coupling my microservice’s code? You could use a Kubernetes Custom Resource to indicate all the information about that type of record and, the microservice in charge of the database, read your Custom Resource and insert the special type of record accordingly.
Future work
We are missing some important concepts in this article, like Kubernetes Controllers, or advanced configurations of the CRDs. When you start to think about Custom Resources in the real world (production), you will need them.
Speaking of which, how is the experience using Custom Resources in production? is the WATCH API working nicely all the time?, what about authorizing applications to read a set of Custom Resources?
These topics will be covered in future articles.
Summary
We reached the end of this article! I hope you enjoyed it as I did writing it. We covered, so far, what a Kubernetes Custom Resource is and how it’s defined. Then, we explored all this through a Hello World exercise where we exposed a Kafka configuration to be used by (potential) microservices living in a Kubernetes cluster. Finally, we end up describing some use cases, focused on the decoupling of microservices, and we let the window open for future articles about this interesting feature.
I must confess that I’m really engaged with this feature, Custom Resources, that Kubernetes offers to its customers. The easy way in which you can get the job done and the flexibility that gives you, as a developer, opens a great window within the Kubernetes world.