
Apache Kafka is one of the most used open-source distributed event streaming platforms when we talk about event-driven microservices architecture. This system brings great features, such as scalability handling, data transformation, and fault-tolerance, among others, that make Apache Kafka so popular for infrastructure, architecture, and developer teams. Micronaut is a modern Java framework, with a very low memory footprint, very suitable for cloud-native Java microservices.
In this article, we will drive a quite simple and fast implementation, that will consume messages from a Kafka topic, thanks to the Micronaut framework and its Micronaut Kafka integration. Engage!
Apache Kafka – A Brief Introduction
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
kafka.apache.org
That said. Apache Kafka, or just Kafka, is delivered as a cluster, made of several brokers (servers), handling the messages that the different applications will produce (add) and consume (get). With this basic information, you can realize some interesting use cases that you can solve with Kafka. Decoupling microservices to transmit information across an event-driven architecture is one of them.
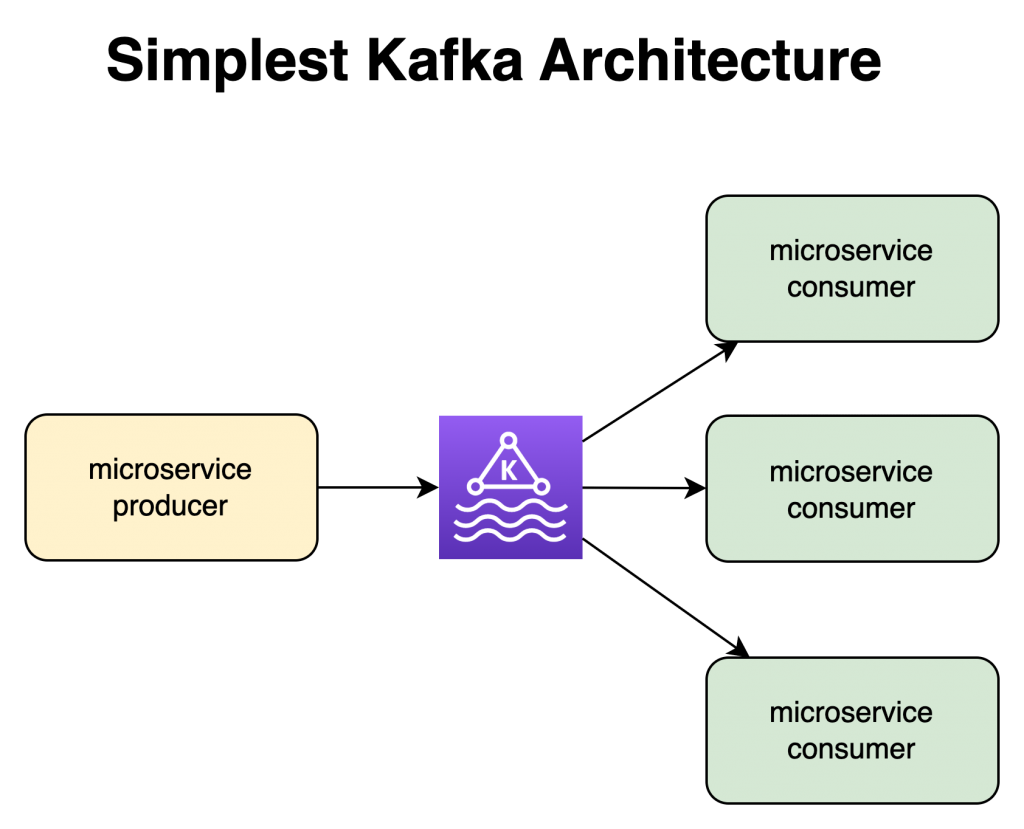
Apache Kafka offers many important features, like Kafka Streams, which I love, and that solves a bunch of many other more sophisticated use cases.
I will keep the focus on the publish/subscribe use case in the current article though, and, more concretely, how easily it can be implemented via Micronaut.
What are gonna do?
Let’s summarize what we are going to do from here. Our main goal is to implement a REST microservice that provides the messages consumed from a Kafka topic as a response.
For this, first, we will create a basic Micronaut Java application, with the Kafka libraries. After, we will go with the most important part: the Kafka consumer; explaining a bit about how it plays in the Micronaut framework. We will finish by storing the read messages in an in-memory storage and exposing an API that will return the list of messages stored over there.
All the code within this article can be found on this Github repository.
Kafka Infrastructure
As a developer, the infrastructure for the Kafka cluster is something that will be provided by your SRE/DevOps team, meaning most likely you will be capable to focus directly on how to implement over Kafka. However, in this article, I provide a docker-compose with the infrastructure required and used in the next chapters.
Skeleton Of The Microservice
To create the basic Micronaut application to manage Kafka, we can use a command like this (or use the Micronaut Launch directly from the web).
mn create-app --features=kafka com.example --build=gradle --lang=javaThis will create a Gradle project, for Java language, that comes with the Kafka libraries to produce messages. Also, it comes with the Netty server, which means that, once we run it, the Netty server will start and keep waiting for requests. This is important in our example because, thanks to this, we achieve 2 things:
- The service is up for listening into Kafka and “do something”
- And also respond to requests to access the information read from Kafka
Now, let’s jump into the Kafka consumer.
Implement The Consumer
Now, we enter in the most important part: How to consume messages from a Kafka topic. The reality is that this is very simple in Micronaut because you have just to annotate a class and a method.
Your class, whatever you want to name it, should have the @KafkaListener annotation. This annotation will tell the framework that, when your application runs, should create a Bean to listen to a Kafka topic, based on the configuration included in the application.yaml file.
However, we need something else. We have to tell the framework from which topic should consume and the method that will process the message/s read from the topic. The annotation @Topic is the one to use for the method, indicating (as a String) the name of the topic.
Here you can see an example of a KafkaListener.
@Slf4j
@KafkaListener(offsetStrategy = OffsetStrategy.SYNC_PER_RECORD)
public class MyKafkaClientConsumerImpl {
@Topic("my_topic")
public void readWhatEver(String message) {
log.info("Message received: {}!", message);
}
}Once again, you can see that no matter the name of the class or the name of the method that will be used to consume from the topic. The important parts here at the annotations and the object received as a parameter in the signature of the method annotated with the @Topic. In the example above, the type of object is a simple String, but it could be a complex Protobuf object. Also, in this annotation, you will indicate the name of the Kafka topic to consume from.
So far so good. At least, we are printing the messages consumed from Kafka. However, we said we want to get those messages from an endpoint, right? So, next, we will add the storage of the messages in this listener and later an endpoint to read from that storage.
Storing Messages
For storing the messages we will not go wild. We will have a simple data structure in memory; a Java object that contains a List of messages. So, this would be the look and feel of the Java storage.
@Slf4j
@Singleton
public class MemoryServiceImpl implements MemoryService {
private final ArrayList<String> store;
public MemoryServiceImpl(ArrayList<String> store) {
this.store = store;
}
@Override
public void store(String obj) {
store.add(obj);
log.info("Object stored in memory! {}", obj);
printStore();
}
@Override
public void printStore(){
store.stream().peek(a -> log.info("Element of the store: {}", a.toString()));
}
@Override
public ArrayList<String> getStore() {
return store;
}
}Now, we will modify the Kafka listener created before, to include access to this storage. This is how does it look like.
@Slf4j
@KafkaListener(offsetStrategy = OffsetStrategy.SYNC_PER_RECORD)
public class MyKafkaClientConsumerImpl implements MyKafkaClientConsumer {
private final MemoryService memoryService;
public MyKafkaClientConsumerImpl(MemoryService memoryService) {
this.memoryService = memoryService;
}
@Override
@Topic("my_events")
public void readWhatEver(String message) {
log.info("Message received: {}!", message);
memoryService.store(message);
}
}All right! So far, what we have is a Kafka Listener that is able to read from a Kafka topic and store the messages in a list. Well, next stop: accessing the information from an endpoint.
Expose Messages Through An API
Last ride! For this exercise, I’ve created a Controller and a Service layer to access the same memory storage accessed by the Kafka Listener. Starting from the “bottom”, the Service to access the messages.
@Singleton
public class HelloServiceImpl implements HelloService {
private final MemoryService memoryService;
public HelloServiceImpl(MemoryService memoryService) {
this.memoryService = memoryService;
}
@Override
public String readFromKafka() {
ArrayList<String> memory = memoryService.getStore();
String ret = memory.stream().collect(Collectors.joining(", "));
return ret;
}
}And now the controller which will accept the HTTP requests and use the service defined above.
@Controller("/hello")
public class HelloController {
private final HelloService helloService;
public HelloController(com.example.service.HelloService helloService) {
this.helloService = helloService;
}
@Get
public HttpResponse<String> hi() {
return HttpResponse.ok(helloService.readFromKafka());
}
}Workflow
Just to be sure that we did not lose track of the iterations on the different elements for this exercise, in the picture below you can see how the communication among the different elements is happening.
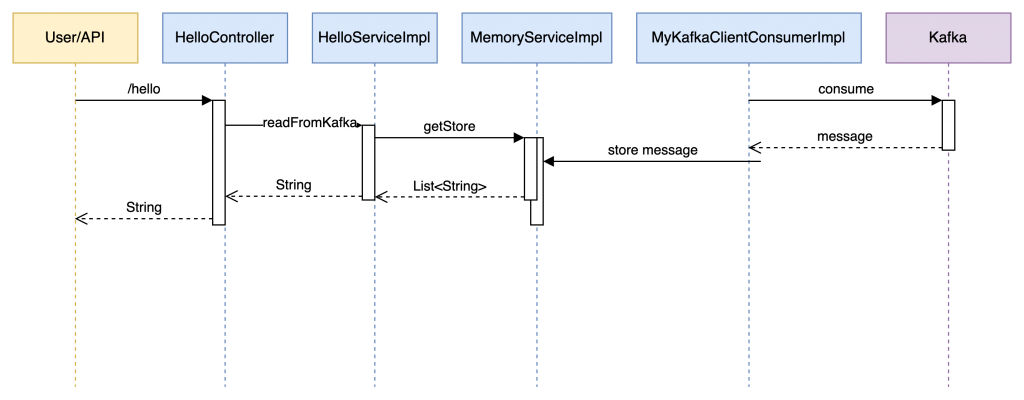
How To Run The Project
This was so much fun, we finished the exercise!. Now, let’s see it flying. First, we have to bring the infrastructure up.
cd docker-compose/
docker-compose upNext, let’s inject some messages into the Kafka topic, so that when the service starts it will have already some messages to consume.
cd docker-compose/data/
docker-compose exec kafka bash -c "
kafka-console-producer \
--bootstrap-server kafka:9092 \
--topic my_events \
--property 'parse.key=true' \
--property 'key.separator=:' < messages.txt"By the way, you always can check the topics that are created on the topic using this command.
docker-compose exec kafka kafka-topics --list --bootstrap-server kafka:29092Well, data loaded! let’s run the service
./gradlew runYou should see some log lines, from the KafkaListerner, consuming the messages we ingested before. Finally, let’s call the endpoint to see that data.
curl http://localhost:8080/helloAnd yes, there it is, the list of messages.
message 1
message 2
message 3
message 4
message 5Future Work
As you can see, this was a small exercise about how to consume from Kafka. You can imagine that, in real scenarios, the complexity of the consumption process is higher.
Because of this, some important themes should be tackled in future articles here. Themes like the usage of complex objects consumed from Kafka, by using Protocol Buffers for example. Also, the usage of Kafka Streams, which is a totally different world, and addresses a different set of use cases than just produce/consume. Anybody said testing? Yes, how do we test our Kafka-based applications? Maybe by leveraging Testcontainers technology.
Summary
All right dear reader! We end this article.
To summarize, we achieved the implementation of a service that is able to read messages from Kafka and make them available, through an API, to the users. The key points were the annotations that the Micronaut framework gives us and the way to make the information consumed to the exposed endpoint.
In future articles, more advanced exercises will be driven, to see all the power of Apache Kafka technology and the use cases related.
Remember that you can find the source code at https://github.com/marcosflobo/kafka-consumption-micronaut