
GraphQL with Micronaut
Reading Time: 6 minutesGraphQL is an open-source query language that is getting a lot of popularity in the last years and brings some new ways to access information. Because of that, GraphQL is gaining traction among developers due to its flexibility to query and retrieve data. Together with the Micronaut Framework, Software Engineers can deliver value fast and in a decoupled way.

In this article, we will see the incipient power of GraphQL by creating a simple Micronaut-based GraphQL server from the scratch. Engage!
About GraphQL
What GraphQL is? From the official website:
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
graphql.org
Facebook started GraphQL development in 2012 and released it in 2015. GraphQL was moved on 7 November 2018 to the newly established GraphQL Foundation, hosted by the non-profit Linux Foundation.
Wikipedia https://en.wikipedia.org/wiki/GraphQL
You can find the original specification of GraphQL, the one created by Facebook, in this link.
This language, created by Facebook (now Meta), provides a web API approach in which clients define the structure of the data to be returned by the server. And this is one of the most important benefits I see in GraphQL in comparison to REST; if the client needs less or more data, with REST you have to change the Data Transfer Object (DTO) in both the server and client, but with GraphQL there is no need; the client asks for what it wants.
We could list 3 main important characteristics that could help you, as a developer, decide if this technology helps you to solve your case
- Permits the client to define exactly what data it is interested in.
- It could be used to get data from multiple data sources and join them in one single response.
- It uses a type system to describe data.
Use Case
After the introduction to the technology (not doing about Micronaut, since I did in other articles), let’s define the use case we want to solve. Let’s go with something very basic.
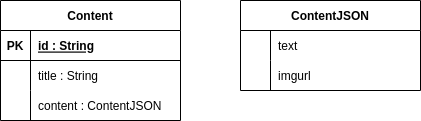
We have a storage of content. That content is defined by a set of attributes and, one of them, is able to store a JSON value. We need an API that is able to browse that content.
Micronaut GraphQL Server
Finally! Some coding. What we are going to do is create a Micronaut-based application that exposes a GraphQL API and such API allows us to search by Content ID. Please note that you can find the whole code in this GitHub.
Let’s create the app
mn create-app com.marcosflobo.graphql-server --build=gradle --lang=javaIn case you do not have the mn command installed, you can go to the Micronaut Launch, add the GraphQL feature, and download the project.
Create GraphQL Schema
All right! we have the application loaded in our favorite IDE, now, first things first. We have to create our GraphQL schema, based on the information we want to expose. In a Micronaut project, we can create this file in src/main/resources directory.
type Content {
id: ID
title: String
content: ContentJSON
}
type ContentJSON {
text: String
imgurl: String
}
type Query {
contentById(id: ID): Content
}As you can see, following the GraphQL syntax, we have 2 types, since we have 2 linked objects. In the end, I add the query Type, so we expose a way to query our data from the GraphQL API.
Data Fetcher
I will not bother you with the creation of the data model. You have it here. Basically, you have to create the classes (annotated with @Instrospective) to model as it’s in the GraphQL schema. Just for you get not get surprised, you can find here how our repository layer (storage) looks like. Let’s jump now to the important part: the data fetchers.
Data fetchers can be also known as “Resolvers”. A “Resolver” function is a place where GraphQL finds out the type or the field and gets its value from the configured database/s, cache, other APIs, etc, and returns data back to the client.
With a Data Fetcher, we bind the GraphQL schema, and our domain model and execute the appropriate queries in our datastore to retrieve the requested data. Let’s see the code and later I explain a couple of important points.
import com.marcosflobo.model.Content;
import com.marcosflobo.repository.DbRepository;
import graphql.schema.DataFetcher;
import jakarta.inject.Singleton;
@Singleton
public class GraphQLDataFetchers {
private final DbRepository dbRepository;
public GraphQLDataFetchers(DbRepository dbRepository) {
this.dbRepository = dbRepository;
}
public DataFetcher<Content> getContentBydIdDataFetcher() {
return dataFetchingEnvironment -> {
String id = dataFetchingEnvironment.getArgument("id");
return dbRepository.findAllContents()
.stream()
.filter(content -> content.getId().equals(id))
.findFirst()
.orElse(null);
};
}
}In line 18, we use the data fetcher to access the GraphQL environment and get the parameter id, which should come in the request for “get content by ID”. Once we have that value, we can access the repository layer to get the right record based on the ID value coming in the request.
GraphQL Factory
The last step, create the Factory of GraphQL object, so the application will be able to find the right bean to process the requests. This class is meant to return the GraphQL object for our Schema, the one that we created before within the resources directory.
import graphql.GraphQL;
import graphql.schema.GraphQLSchema;
import graphql.schema.idl.RuntimeWiring;
import graphql.schema.idl.SchemaGenerator;
import graphql.schema.idl.SchemaParser;
import graphql.schema.idl.TypeDefinitionRegistry;
import graphql.schema.idl.TypeRuntimeWiring;
import io.micronaut.context.annotation.Bean;
import io.micronaut.context.annotation.Factory;
import io.micronaut.core.io.ResourceResolver;
import jakarta.inject.Singleton;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.Optional;
import lombok.extern.slf4j.Slf4j;
@Slf4j
@Factory
public class GraphQLFactory {
@Bean
@Singleton
public GraphQL graphQL(ResourceResolver resourceResolver, GraphQLDataFetchers graphQLDataFetchers) {
SchemaParser schemaParser = new SchemaParser();
TypeDefinitionRegistry typeDefinitionRegistry = new TypeDefinitionRegistry();
// Read the GraphQL schema definition
Optional<InputStream> graphQlSchemaFile = resourceResolver.getResourceAsStream("classpath:schema.graphqls");
if (graphQlSchemaFile.isPresent()) {
// parse the schema into the registry object
typeDefinitionRegistry.merge(
schemaParser.parse(new BufferedReader(new InputStreamReader(graphQlSchemaFile.get())))
);
// Lets wire the Schema definition with the right data fetcher
RuntimeWiring runtimeWiring = RuntimeWiring.newRuntimeWiring()
.type(TypeRuntimeWiring.newTypeWiring("Query")
.dataFetcher("contentById", graphQLDataFetchers.getContentBydIdDataFetcher()))
.build();
// Finally, let's "join" the wire and the GraphQLSchema to ge returned on the GraphQL object
SchemaGenerator schemaGenerator = new SchemaGenerator();
GraphQLSchema graphQLSchema = schemaGenerator.makeExecutableSchema(
typeDefinitionRegistry,
runtimeWiring);
log.info("Returning GraphQL object from Schema found");
return GraphQL.newGraphQL(graphQLSchema).build();
} else {
// GraphQL file not found, so we return an empty schema
log.warn("The GraphQL schema was not found, returning an empty GraphQL object");
return new GraphQL.Builder(GraphQLSchema.newSchema().build()).build();
}
}
}The most important part of the code above (probably) is line 38 on which we create the wire between the query and its “method” (contentById) exposed and the right data fetcher implementation. Later those lines, it’s just a matter of “joining” the wire with the GraphQLSchema that will be included in the GraphQL object to be returned.
Run the app
All right fellas! Those were the most important parts of the exercise. The rest of the code can be found on GitHub. Now, it’s time to test if this actually works. Of course, first, run the app:
$ ./gradlew runNow, in another shell, let’s run this CuRL command:
$ curl --location --request POST 'http://localhost:8080/graphql' \
--header 'Content-Type: application/json' \
--data-raw '{"query":"query{contentById(id: \"1\") {id, title}}","variables":{}}'
{"data":{"contentById":{"id":"1","title":"First content"}}}Brilliant! We got the “First content”! The first thing to notice, from the command above, is that we have to use the /graphql endpoint and the POST method in our request. Also important to mention how the body of the request is made, and “almost” can be inferred from the Schema.
Future Work
As you could see, in this article we are using the memory of the application as the storage, which is something you will not find in real life (a part of caches maybe?). Also, we are doing a simple query to get the object of the first level by ID.
In future articles, we should go deep into the potential of GraphQL by adding a layer to a real database and making queries that are able to filter by the keys within the JSON value stored in the content column. For that, the power of PostgreSQL and its JSONB type of field could provide the capability for our clients to perform a more fine-grained query across the data store.
No less important is the performance. We should have another article to compare GraphQL with the REST technology, since such information would help you, as Software Engineer, to take the right decision to solve your use case.
Summary
One more article my dear readers! In this case, we discovered GraphQL technology, a query language that allows clients to request the precise information they want, saving network resources and time, and we did it by implementing a simple Micronaut-based application that exposed an API to get content by ID.
I would love to hear about your experiences with GraphQL implementations. Reach me on Twitter or Mastodon, happy to conversate about GraphQL!